在初步學習了Python、Gradio、Azure、SQL&NoSQL、LINE BOT之後,鐵人賽也跑到將近一半了!加油!
終於要開始做我的AI Side Project--每拍呷-營養標示一拍就懂!
目標:兩周內完成
(瑟瑟發抖)
以下資訊是否常常看得您眼花撩亂、或是乾脆不看呢?(示意範例,非真實食品)

黃線左邊的是成份表,右邊的是營養標示,其實對有些長輩來說,並不是很好閱讀。

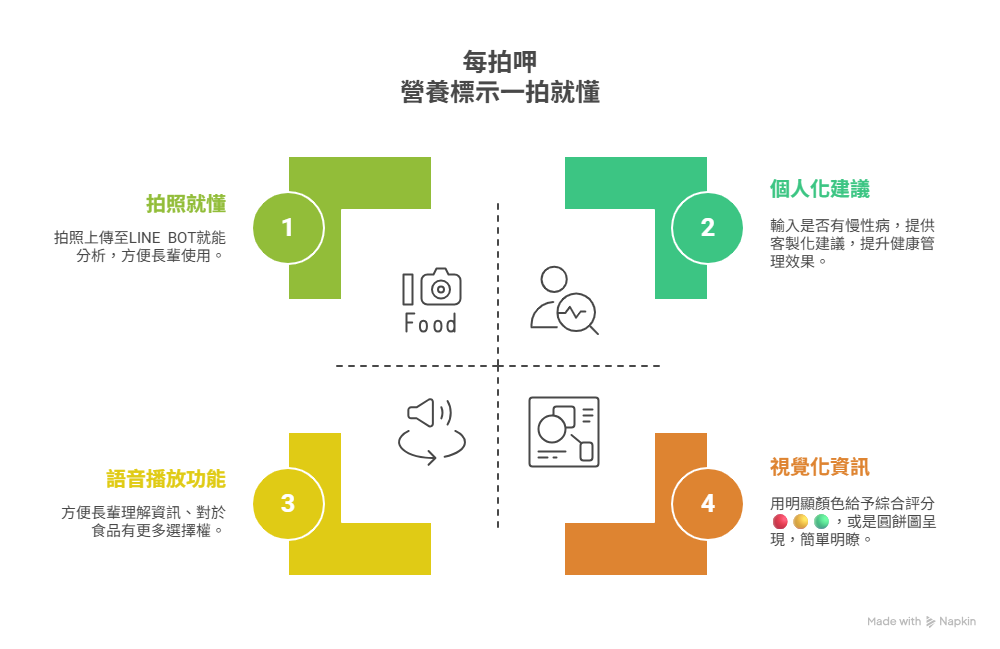
我想做的「每拍呷」是幫助長輩看懂營養成份標示的LINE BOT,許多長輩因營養標示字體太小、內容複雜難懂,因此放棄查看營養標示。「每拍呷」旨在透過簡單、直觀的方式,讓長輩只要一個動作:拍照上傳LINE,就能看懂營養成份標示,吃的更安心、也更能有趣地掌握自己的飲食健康,每次拍照都好呷!
使用情境
智慧光學辨識 (OCR):
辨識食品包裝上的營養成分標示與成分內容,克服字體小、排版複雜等挑戰。(若拍照失敗,也支援文字訊息輸入)
生成式AI:
(Bonus)語音播放功能(TTS):
預計使用Azure的TTS服務,提供分析結果的語音朗讀功能,方便視力不佳的長輩「聽懂」食物資訊。
如果有台語服務就更讚了。待我行有餘力再來想辦法研究這一塊...
(Bonus)db:若要記錄用戶的上傳內容並進行互動(例如:蒐集到十樣綠燈食品就會頒發數位獎狀),就需要做資料庫了,待我行有餘力再來想辦法研究這一塊...
拍照上傳
用戶用手機拍攝營養標示與成分表。
⬇️
OCR 辨識與數據提取
LINE BOT接收照片,透過Azure OCR服務辨識文字,並提取熱量、脂肪、糖、鈉、份量等關鍵數據。
⬇️
生成建議與評估
AI根據辨識出的數據,結合用戶預設的健康標準,生成易懂的營養分析、紅黃綠燈評分和個人化建議。
⬇️
文字轉語音(選配功能)
若用戶啟用語音播放功能,分析結果文字將轉換為語音,播放給長輩聽。
⬇️
回傳 LINE 聊天室
將分析結果(文字、表情符號、或圖像)透過多個對話泡泡回傳至LINE聊天室。
由於我是第一次做Side Project,進度內容是跟Gemini一起討論的,實際進度就做滾動式修正吧!且戰且走XD
第一週:基礎建構與數據核心 (D1 - D7)
D1:研究國人營養素參考攝取量(DRIs)的最新標準,確立營養標準依據與數據轉換邏輯。
D2:細化所有營養素的判斷條件,並建立生成建議的範本。整理個人化建議的觸發條件(例如:若用戶有高血壓標籤,則鈉含量只要超過 X 值就給予警示)
D3:完成 OCR 服務的基礎設定與初步測試。撰寫一個Python程式碼,使用一張營養標示圖片進行OCR服務呼叫。
D4:能從 OCR 原始結果中精準提取所需的營養數據。找出營養標示和成分表中的關鍵文字(如:熱量、脂肪、糖、鈉、每一份量、本包裝含幾份)精確提取這些數值。
D5:建立 LINE BOT 雛形,能接收用戶訊息。
D6:LINE BOT 圖片接收與處理
D7:前後端整合,確保資料流從 LINE 收到圖片 -> OCR 辨識 -> 數據提取 -> 數值計算 -> 回覆 LINE 的整個流程暢通。
第二週:智慧解析與用戶體驗優化 (D8 - D14)
D8:紅黃綠燈判斷與基礎生成建議,初步生成白話文建議
D9:讓 AI 生成的建議更生動有趣、貼近長輩語氣。考慮如何在建議中加入一些關懷語句或鼓勵。
D10:個人化建議與 LINE 回覆介面優化,將分析結果拆解為多個對話泡泡。使用放大字體、粗體字
D11:錯誤處理與全面性測試
D12:進行 MVP 的端到端測試,並收集初步用戶回饋。邀請至少 2-3 位測試者
D13:根據回饋調整與功能強化
D14:專案總結與部署準備(如果時間允許且有部署需求)
考量到 14 天的緊湊時程,我建議在 MVP 階段暫時不加入「文字轉語音」功能。現階段應將重心放在核心的 OCR 辨識、AI 精準分析和高可讀性的文字回覆上。一旦 MVP 穩定且用戶體驗良好,文字轉語音可以作為第二階段的優化目標或加分項目。實現語音播放需要額外的 TTS API 串接與音檔處理,可能會顯著增加開發時間。


 iThome鐵人賽
iThome鐵人賽